Evaluating MCP Shopping Agents: Why Tool Design Beats Model Scale
The shift from single-turn chatbots to multi-step agents has quietly broken traditional evaluation. When an agent uses the Model Context Protocol to call tools, the path to an answer matters as much as the answer itself. The path includes which tools the agent picks, how it forms arguments and how it recovers from errors. This is all missed by end-state grading.
This is not a new observation. AgentBench 1 showed that models excelling on static benchmarks often fail in tool-using environments, with poor long-term reasoning and weak multi-step instruction following as the primary bottlenecks. What was missing was a principled way to evaluate agents as they actually operate: multi-turn, tool-mediated, and route-dependent.
From Answer Grading to Trajectory Evaluation
Early agentic evals tried exact-match JSON parsing. Failing an agent because it
formatted a payload as {"price": 199.99} instead of {"price": 200}, when
both were accepted upstream, proved too brittle. The field has since moved
toward deep trajectory evaluation: scoring the full sequence of tool calls and
their outcomes, not just the final response.
MCPEval 2 formalised this split between syntax (tool call matching) and semantics (LLM judge analysis). TRAJECT-Bench 3 introduces metrics for tool dependency chains and explicitly states that evaluating the final answer alone is insufficient.
The practical obstacle is raw MCP transport logs: highly verbose, full of protocol metadata, difficult for an LLM judge to parse reliably. The solution is a two-stage approach. A deterministic normalization script intercepts the logs first, producing a clean Evidence Trace: just the sequence of tool calls, arguments, success/failure status, and result previews. The judge then evaluates only this normalized trace, keeping mechanical execution separate from semantic scoring. This draws from profile-aware LLM-as-a-judge work 4, where structuring the context presented to a judge, rather than feeding it raw noisy input, improves evaluation reliability.
How We Ran the Sweep
We built a four-stage pipeline orchestrated with DVC: persona generation, conversation simulation, trace normalization, and trajectory judging.
Grounded synthetic personas. Each run generates 30 synthetic shoppers per
product catalogue. Before profile creation, the pipeline issues broad
search_catalog calls against the live MCP server and injects extracted
categories, brands, and price ranges into the prompt. Persona psychographics are
structured around VALS, OCEAN, JTBD, and benefit-segmentation frameworks, with
conversation depth sampled from 2–10 turns. Agents cannot succeed by parroting a
product name buried in the profile.
Two-agent simulation. A persona agent plays the shopper. The MCP agent under
test connects to a specific route, receives server instructions via the standard
initialize handshake, and decides when and how to call tools. Failed tool
calls are retried with backoff; a conversation is marked failed only after
repeated consecutive failures, so transient errors do not silently pass as
success.
Experimental sweep. The core comparison is a paired variant sweep: each cell
combines one MCP endpoint, one matching agent prompt, one simulation model, and
one catalogue index. We evaluate three retail catalogues across four simulation
models (Ministral-3B, Qwen3-8B/14B/32B) and eight MCP routes. The routes are
deliberately additive: the search route exposes only search_catalog, filtered
adds constraint-based filtering on top of that, and full with facets layers in
facet discovery and the remaining tools. Utility routes like weather and
calculator test general tool-calling behaviour outside the product domain. The
GraphQL route sits apart from this ladder entirely. That yields hundreds of
cells, each with 30 conversations.
The GraphQL route is the deliberate stress case, inspired by the Apollo GraphQL
pattern of exposing a single flexible query interface. It exposes a single
graphql_query tool against the same underlying catalogue that other routes
serve through curated tools like search_catalog and get_catalog_facets. Same
data plane, different interface contract.
Trace normalization. A deterministic script distills each conversation into an Evidence Trace: a chronological sequence of tool actions, each recording the tool name, parsed arguments, success/failure, error messages, result counts, brand/type signals, and a compact product preview. Budget, category, and brand constraints are snapshotted at each step so the judge can assess whether retrieval matched intent.
LLM-as-judge scoring. An LLM judge (Nemotron 3 Super via OpenRouter) scores each normalized trace on three integer dimensions (1–3):
| Dimension | What it measures |
|---|---|
| Need match | Did tool queries and returned previews fit the shopper's stated constraints across turns? |
| Tool execution | Quality of tool choice, argument formation, and recovery from empty or off-target results. |
| Trust / grounding | Are assistant claims supported by tool evidence, without fabricated product details? |
The rubric treats search_catalog result previews as canonical evidence of what
the shopper saw, penalizes redundant in-chat product catalogs, and rewards
constraint-aware reformulation over fluent prose. The judge runs at
temperature 0. Per-cell scores are bootstrapped into confidence intervals and
rolled up into route × model × catalogue tables.
The Results: Interface Contract Dominates
The sweep split cleanly. Curated MCP routes produced usable shopping agents. The GraphQL route did not.
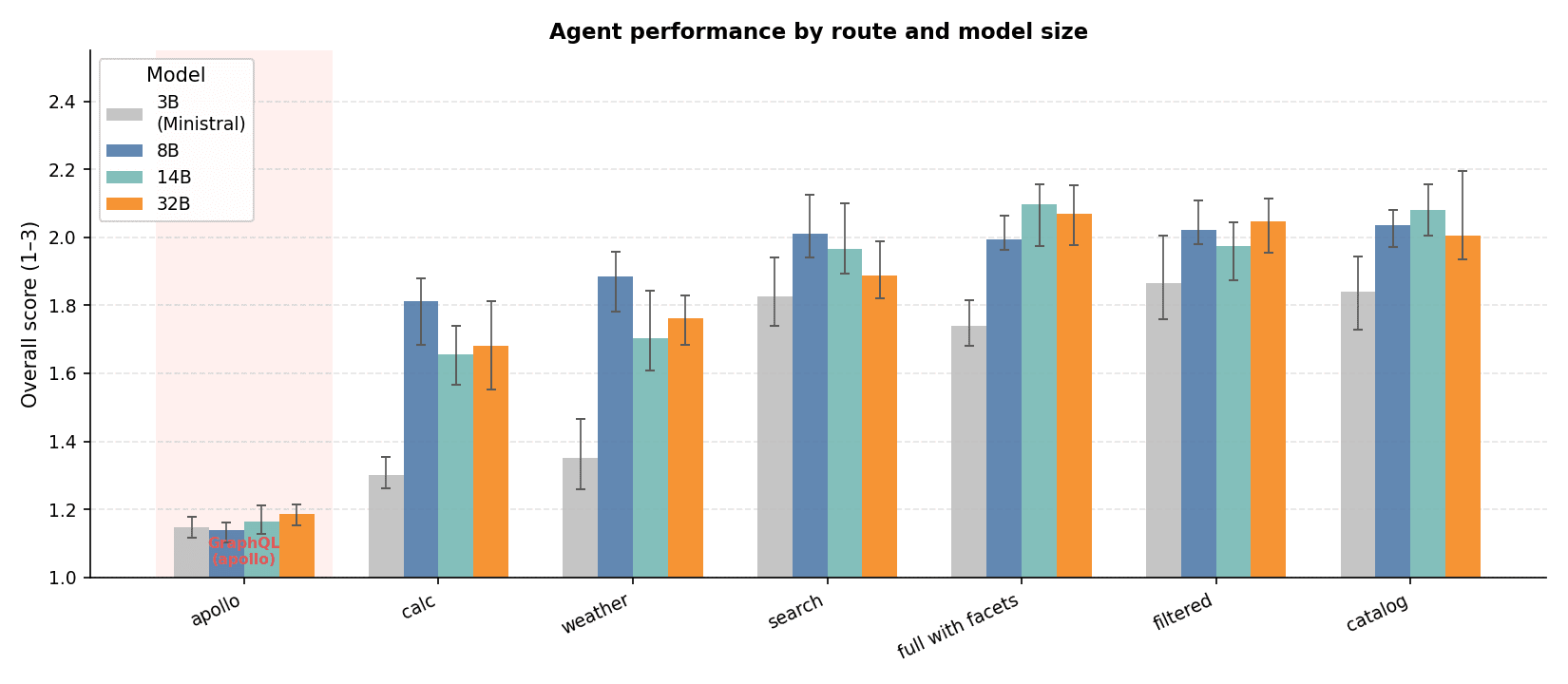
The GraphQL route failed across the board. Qwen3 models averaged roughly 1.14–1.19 overall on the GraphQL route versus ~2.0 on search and full with facets routes. Agents did not learn the schema; they guessed it, inventing field names, nesting, and filter types until queries failed on the first tool turn. Need match and tool execution sat at the rubric floor across 8B, 14B, and 32B. In the worst cells every conversation failed; even the best cells lost roughly half. The fundamental issue is that open-ended GraphQL authoring against an underspecified interface is a schema-memorization task, not a reasoning task. Smaller models have no basis for memorizing a schema they have never seen.
Bigger models did not fix this. Qwen3-32B on the GraphQL route was no better than 8B. The bottleneck is the interface contract, not context window size. No amount of additional capacity rescues an agent that must hallucinate a schema on every turn.
Curated tools changed the picture. search_catalog and related operations
give agents a small, typed contract instead of a schema to hallucinate. Qwen3-8B
on search-only MCP reached ~2.0 with zero conversation failures, credible
discovery at a fraction of frontier-model cost.
Scale bought little once the interface was right. Search peaked at 8B and declined slightly beyond that; full with facets continued improving to 14B before plateauing. Either way, the main jump is 3B → 8B — scaling from 8B to 32B returns little. Better tool design moved the needle far more than bigger models. Ministral-3B still struggled everywhere, so there is a floor, but that floor is 8B, not 32B.
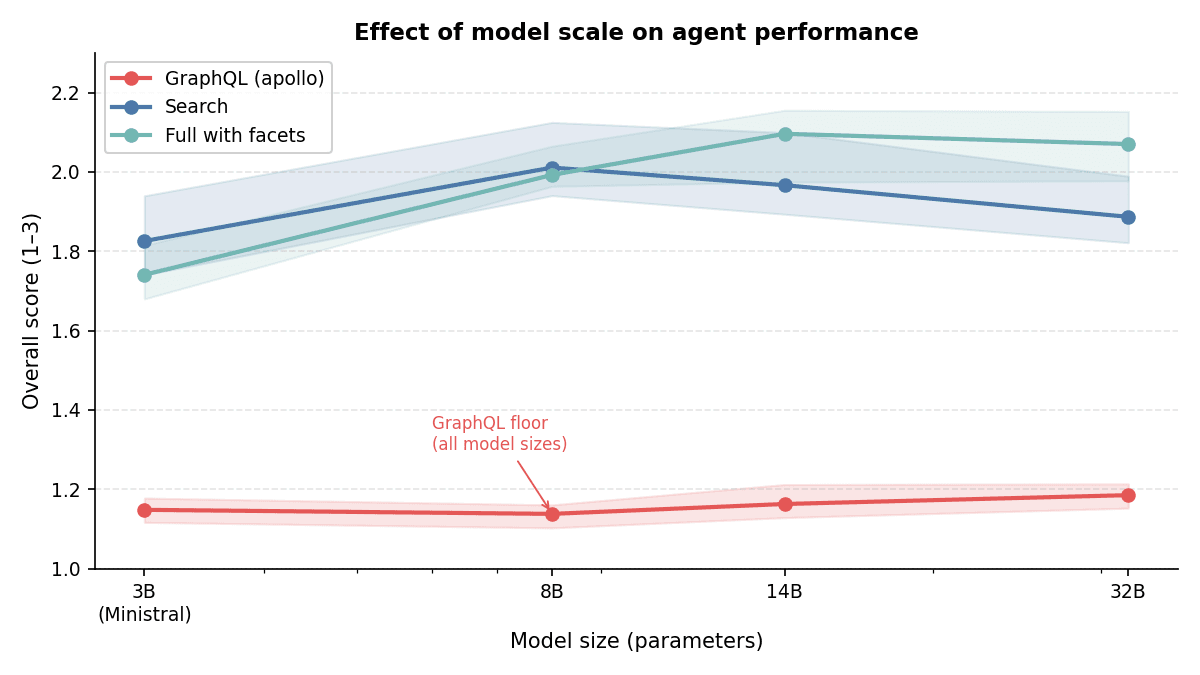
The practical lesson is a modular ladder. Search-only MCP is a strong, cheap baseline. Adding filters or the full with facets toolset improves specific capabilities like constraint-aware filtering and richer discovery, rather than rescuing broken agents. You compose the surface to fit the product requirements; you do not ask the model to write GraphQL from imagination.
Bottom line: raw GraphQL in MCP is a stress test, not a production interface. Curated MCP tools are what make mid-size models work. Past 8B, invest in tool design before model scale.